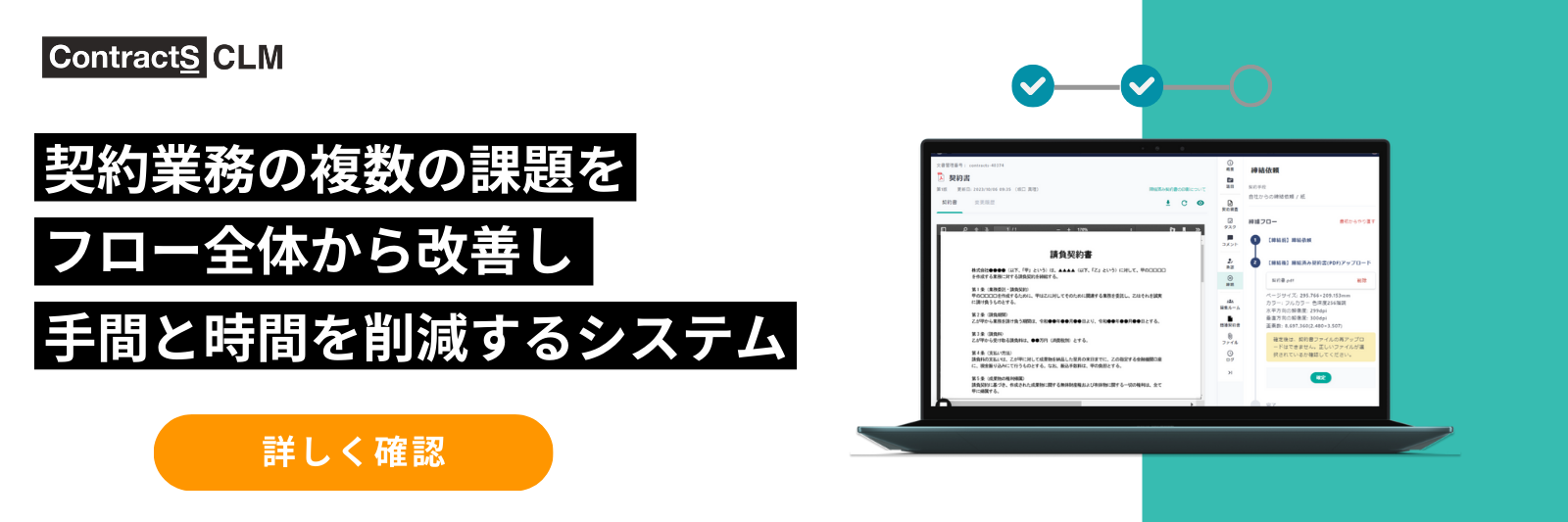
ノウハウ 契約棚卸しはAIエージェントに任せる時代へ|オープン型CLM × 自律型AIで実現する契約インベントリ運用
契約棚卸しはAIエージェントに任せる時代へ|オープン型CLM × 自律型AIで実現する契約インベントリ運用

契約棚卸しが法務の積年の課題である理由
ある一定規模を超えた企業の法務責任者にお尋ねすると、たいていの場合「自社の有効な契約が今いくつあるか、即答できない」という回答が返ってきます。これは決して怠慢ではなく、構造的な問題です。
契約は、法務だけが扱うものではありません。営業、調達、人事、開発、経営企画——あらゆる部署が、それぞれの取引や採用、業務委託の場面で契約を交わしています。締結された契約書は、紙のままキャビネットに保管されたり、各部署のファイルサーバーやSharePoint、個人PCのデスクトップに残されたり、メール添付のまま放置されたりします。電子契約の導入が進んでも、過去の紙契約は別管理のままで、結果として「全社の契約がどこに何件あるのか、誰も把握していない」状態が、エンタープライズではむしろ標準になっています。
この状態を放置すると、いくつもの経営課題が顕在化します。M&Aのデューデリで自社契約を網羅的に開示できない、海外子会社の契約条件を把握できないためグループ全体のリスクを評価できない、自動更新条項を見落として不利な条件で契約が更新されてしまう、サブスクリプション契約の費用が二重に発生していたことに気づくのが半年遅れる——いずれも、契約の所在と中身を把握できていないことが原因です。
そこで多くの企業が「契約棚卸し」プロジェクトを立ち上げます。しかし、人手で数千〜数万件の契約を確認していくのは現実的ではなく、派遣社員や外部のリーガル業者に委託しても、コストと期間が膨大で、しかも質のばらつきが避けられません。OCRと表計算ソフトを組み合わせた半自動化を試みた企業もありますが、メタデータの抽出精度や条項の判断には人間の介在が必須で、結局「棚卸しは始めたものの完遂しないまま放置」というケースが後を絶ちません。
他方で、法務業務全般を見ると、ChatGPTやClaudeをはじめとする生成AIが日常業務に深く入り込んでいます(AIとChatGPTは契約業務をどう変える?実務での活用法と注意点を解説)。社内規程の改訂、社内問い合わせ対応、海外法務調査、覚書の確認——契約レビュー以外の場面でも、AIなしの法務業務は考えにくくなりつつあります。
この状況下で、長年の積年の課題である「契約棚卸し」にようやく現実的な解決策が見えてきました。それが、自律型AIエージェント × オープン型CLM の組み合わせです。
そもそも契約棚卸しとは(3つのスコープ)
「契約棚卸し」と一言で言っても、実は対象とする業務の性質によって、大きく3つのスコープに分けられます。
| スコープ | 対象状態 | 主な作業 |
|---|---|---|
| 1. 初期棚卸し(インベントリ化) | 紙・PDF・ファイルサーバー・各部署ローカルに契約が散在。CLM未導入またはCLM導入直後 | 契約原本の収集 → OCR → メタデータ抽出 → CLMへの正本登録 |
| 2. クレンジング棚卸し(メタデータ補完) | CLM運用済みだが、過去データの入力品質がバラバラ。表記揺れ・期限空欄・自動更新フラグ漏れが多発 | 既存レコードの監査 → 欠損項目の再抽出 → 表記正規化 → 紐付け修正 |
| 3. 継続的棚卸し(運用フェーズ) | CLMが日常運用フェーズに入っている。期限管理・更新判断・コンプライアンスチェックが日常業務 | 期限接近契約の抽出 → 更新要否判断 → 関係部門への確認 → 再交渉・解約準備 |
本記事では、最も多くの企業が突破に苦労するスコープ1の初期棚卸しを中心に解説します。記事の後半では、初期棚卸しを終えた後の運用フェーズ(スコープ3)への橋渡しまで触れます。スコープ2のクレンジング棚卸しは、初期棚卸しと運用棚卸しのちょうど中間に位置するため、本記事の枠組みを応用して進めることが可能です。
なぜ単発の生成AIでは棚卸しが進まないのか
「ChatGPTやClaudeを使えば、契約の中身は読めるじゃないか」——確かにそうです。1件の契約書をAIに渡して「当事者、締結日、契約期間、自動更新条項を抽出してください」と指示すれば、それなりに正確な結果が返ってきます(Claudeで契約書レビューはどこまでできる?AI活用の実務と注意点に整理したとおり、契約書の要約・差分抽出・論点整理といった単発タスクでは、すでに実用レベルです)。
ところが、これを棚卸し業務として成立させようとすると、単発の生成AIには4つの致命的な制約があります。
制約1:1件ずつしか処理できない
ChatGPTやClaudeのチャットUI上では、1件の契約を読み込ませて結果を確認し、また次の1件を読み込ませる、という逐次処理になります。数千件規模の棚卸しでは、この単純作業を人間が指示し続けることになり、現実的ではありません。
制約2:抽出結果を保存する「正本データベース」がない
チャットの応答として返ってきたメタデータは、コピー&ペーストでExcelやスプレッドシートに転記する必要があります。表記揺れの正規化、重複の検出、後からの再検索といった機能は、表計算ソフトでは限界があります。CLMの本質は「契約の正本データベース」であり、ここに直接書き込めないと、せっかく抽出したデータが活きません。
制約3:多段階の判断・分岐に弱い
契約棚卸しでは、「自動更新の有無」「解約予告期間」「最低契約期間」など、契約類型ごとに見るべき項目が変わります。さらに「自動更新ありの場合は、次回更新日を逆算してアラート対象に登録する」など、多段階の判断・分岐が連続します。これを単発のプロンプトで処理しようとすると、プロンプトが肥大化し、精度が低下します。
制約4:継続運用に乗らない
仮に頑張って初期棚卸しを終えても、半年後・1年後に新たに締結された契約や、修正された契約に対して、また同じ作業を繰り返す必要があります。プロンプトやノウハウが個人に紐づき、業務として継続運用できません。
要するに、単発の生成AIは「契約を1件読む」道具であって、「契約棚卸しを業務として回す」道具ではないのです。
自律型AIエージェント × オープン型CLMという解決策
ここで登場するのが、自律型AIエージェントと、オープン型CLM(OpenCLM)の組み合わせです。
自律型AIエージェントとは
チャットUI上で1回の指示・1回の応答で完結する従来の生成AIと違い、自律型AIエージェントは「目標」を与えられると、必要なツールを自分で呼び出し、多段階の判断を繰り返しながら、ゴールに到達するまで自走するAIのことです。
たとえば「このフォルダ配下のすべてのPDF契約書からメタデータを抽出して、CLMに登録してください」と指示すれば、エージェントはフォルダを一覧し、PDFを1件ずつ読み込み、メタデータを抽出し、CLMのAPIを呼び出して書き込み、エラーがあれば再試行し、進捗を報告する——という一連の流れを自分で進めます。Claude Opus 4.7、ChatGPTのAgent Mode、各種AIエージェントフレームワークによって、こうした自律実行が2026年現在、実用フェーズに入っています。
オープン型CLM(OpenCLM)とは
契約データの正本管理と運用基盤をCLMが受け持ち、レビュー・要約・抽出といったAI処理は外部の汎用AIを接続して利用する、という設計思想を採用したCLM製品群を指します。「使うAIを自由に選べる」「契約データに外部から安全にアクセスできる」「データ・ワークフロー・外部システム連携が疎結合に設計されている」というのが特徴です。オープン型CLMの設計思想と長期戦略上の意義については、ベンダーロックインを避ける法務のAI活用の考え方|Open CLMという新常識で詳しく解説しています。
この二者を組み合わせると何が起きるか
自律型AIエージェントが、オープン型CLMをツールとして呼び出しながら、棚卸し業務を進めます。具体的には、
- エージェントが契約原本(PDF・画像)を読み込む
- メタデータを抽出する(当事者、契約期間、自動更新条項、解約予告など)
- オープン型CLMのAPIを呼び出して、契約レコードを登録する
- 抽出が不確実な部分はフラグを立てて、人間レビュー待ちにする
- 大量バッチを並列で実行する
- エラー時には自動で再試行する
これにより、これまで「人手で数百人月」が必要だった棚卸し業務が、実質的には数日〜数週間で、ほぼ自動化された形で終わるようになります。しかも、エージェントの動かし方は社内のノウハウとして残り、運用フェーズの継続棚卸しにもそのまま転用できます。
ここに、AI内蔵型CLMとの設計思想上の決定的な差が現れます。AI内蔵型CLMは「契約レビューだけを専属AIに切り出す」発想なので、棚卸しのような業務横断的な大量処理が想定外です。オープン型CLMは「契約データの正本管理に徹し、AI処理は外部に委ねる」発想なので、自律型エージェントを接続して棚卸しを進めることが、設計の延長線上で可能になります。
初期棚卸しの5ステップ実務手順
それでは、具体的にどう進めるか。初期棚卸しを5ステップに分解して解説します。法務実務担当者向けに、ContractS CLMのようなオープン型CLMと、Claude/ChatGPT等の汎用AIエージェントを組み合わせる前提で書いています。
ステップ1:契約原本の収集と前処理
まず、棚卸し対象となる契約原本を集めます。電子化されているもの(PDF、Word、画像)はそのまま、紙のものはスキャンしてPDF化します。
ここでの重要ポイントは、**「完璧を目指さない」**こと。全社のすべての契約を最初から集めるのは現実的ではないので、まず「直近5年分の有効契約」「年間取引額が一定以上の契約」「重要事業に関わる契約のみ」など、対象範囲を絞ります。
スキャンしたPDFは、OCR処理を施します。最近の汎用OCR(Adobe AcrobatのAI OCR、Google Document AIなど)は精度が高く、和文・英文ともに実用レベルです。OCR結果が信頼できるかどうかは、サンプリングで数件確認し、文字認識の精度を担保しておきます。
前処理が終わった契約PDFは、エージェントがアクセスできるストレージ(社内のクラウドストレージ、SharePoint、ファイルサーバー)に整理しておきます。
ステップ2:エージェントへのメタデータ抽出指示の設計
次に、自律型AIエージェントに対して「何を抽出するか」を指示する設計を行います。
ここで法務担当者の出番です。エンジニアではなく、法務がリードして抽出項目を設計するのが成功のコツです。なぜなら、抽出すべき項目とその判断基準は、契約類型と自社の業務フローに深く依存するからです。
たとえば、業務委託契約であれば「委託業務の内容」「成果物の権利帰属」「再委託の可否」「秘密保持期間」「契約期間と自動更新条項」を抽出する。NDAであれば「秘密情報の範囲」「目的外利用の禁止」「存続期間」を抽出する——というように、契約類型ごとに項目を設計します。
汎用的な抽出項目(当事者名、締結日、契約期間、契約金額、自動更新の有無、解約予告期間など)は共通項目として固定し、契約類型ごとの追加項目を上乗せする構造にすると、エージェントへの指示が整理しやすくなります。
ステップ3:エージェントによるCLMへの自動投入
設計が終わったら、エージェントを動かします。
エージェントは、ステップ1で用意したストレージ上の契約PDFを1件ずつ読み込み、ステップ2で設計した項目を抽出し、オープン型CLMのAPIを呼び出して契約レコードを作成します。原本PDFも同時にCLMに添付され、メタデータと原本が紐付いた状態でCLMに格納されます。
このステップで重要なのは、**「抽出が不確実な部分はフラグを立てる」**ようエージェントに指示することです。たとえば「契約期間が原本から読み取れなかった」「自動更新条項の有無が判定できなかった」といった場合は、空欄にせず「要レビュー」フラグを立てて、後の人間レビュー工程に回します。
大量バッチを並列で動かせるのも自律型エージェントの強みで、ここで一気に処理速度が上がります。
ステップ4:人間によるサンプリングレビュー
エージェントの抽出が終わったら、法務担当者が結果をレビューします。全件レビューは現実的でないため、サンプリングと「要レビュー」フラグの2軸で確認します。
- サンプリングレビュー:契約類型ごとに5〜10%を抽出し、エージェントの抽出結果と原本を突き合わせて、精度を確認する
- 要レビューフラグ対応:エージェントがフラグを立てた契約を全件確認し、人間が判断して入力する
このステップで、抽出精度の傾向(どの項目で間違いやすいか、どの契約類型で精度が落ちるか)が見えてきます。必要に応じてステップ2の指示設計に立ち戻り、抽出ロジックを改善します。
ステップ5:継続運用フェーズへの移行
初期棚卸しが終わったら、運用フェーズに移行します。ここで重要なのは、初期棚卸しで使ったエージェント設計を、そのまま運用フェーズに転用することです。
新規締結された契約をストレージに置けば、エージェントが自動でCLMに登録する。更新期限が近づいた契約をエージェントが定期的に巡回して、関係部署に通知する——という形で、初期棚卸しの仕組みがそのまま継続運用の基盤になります。
業務利用時の注意点3つ
ここまで読んで「すぐにでも始めたい」と思っていただけたら何よりですが、実務で運用する際には押さえておくべき注意点が3つあります。
注意点1:抽出精度の検証ルールを最初に決める
エージェントの抽出は完璧ではありません。特に、文書のフォーマットがバラバラな過去契約や、図表混じりの複雑な契約では、抽出ミスが起きやすくなります。
これに対応するには、サンプリングレビューの方法と頻度を最初にルール化することが必要です。「契約類型ごとに5%」「金額が一定以上の契約は全件」「初回バッチは10%、安定したら3%に下げる」など、自社の業務リスクに応じた検証ルールを設けます。
また、エージェントが「要レビュー」フラグを立てる基準も明文化しておくと、エージェントと人間の役割分担が明確になります。
注意点2:機密情報の取り扱いと、法人プランの非学習保証
契約書は機密情報のかたまりです。エージェントを動かす際に使うAI(ChatGPT、Claudeなど)のプランは、**必ず法人向けプラン(非学習保証付き)**を選びます。
ChatGPT EnterpriseやClaude Enterprise/Teamプラン以上では、入力データがAIモデルの学習に使われないことが明示的に保証されています。個人プランやAPIの一部プランでは保証が異なるので、契約棚卸しで使うAIプランは情シス・セキュリティ部門と相談の上で選定します。
オープン型CLMを選ぶ理由の一つも、ここにあります。使うAIを自社で選べるということは、自社のセキュリティ要件・コンプライアンス要件に合ったAIを選定できるということです。
注意点3:エージェントの自律性の境界を設計する
自律型AIエージェントは、放っておけば何でも自分で判断してしまいます。実務では、これを意図的に制限する必要があります。具体的には、
- エージェントが書き込んでよい範囲を限定する(CLMの新規レコード作成は可、既存レコードの上書きは不可など)
- 一定の承認フローを組み込む(金額が一定以上の契約は人間承認なしには登録しない)
- エージェントの動作ログを残し、後から監査できるようにする
オープン型CLMでは、こうしたエージェントの権限管理や監査ログを、自社のセキュリティポリシーに合わせて設計できる点が大きなメリットです。
初期棚卸しの先へ:運用フェーズの継続的棚卸しもオープン型CLMだからできる
初期棚卸しは、いわば「過去の負債を一気に清算する」プロジェクトです。これが終わったら終わり、ではありません。むしろ、本当の勝負は継続運用フェーズから始まります。
新規締結された契約を漏れなくCLMに取り込む。既存契約の更新期限が近づいたら、自動更新の有無を踏まえて関係部署に通知する。新しい法令や規制が出たら、対象となる既存契約を一括検索して影響分析を行う——こうした業務は、本来CLMが最も価値を発揮するフェーズです。
ここでも、初期棚卸しで使った自律型AIエージェントの仕組みがそのまま転用できます。エージェントの抽出ロジック、CLMへの書き込み権限、サンプリングレビューのルール——すべてのノウハウが継続運用の基盤になります。
加えて、運用フェーズではAIモデルそのものも進化していきます。Claude Opus 4.7、GPT-5.5といった次世代モデルが登場するたびに、契約読解の精度や多段階推論の能力は向上していきます。「使うAIを選べる」オープン型CLMの設計は、このモデル進化の恩恵を、CLM自体を入れ替えることなく、即座に取り込めるという長期的なメリットをもたらします。
ここが、AI内蔵型CLMとの決定的な違いです。AI内蔵型CLMは、CLMベンダーが選定したAIに固定されます。一方、オープン型CLMは、自社が選んだAIエージェントをCLMに接続するため、AIの進化と契約管理を独立に進化させられます。3年後・5年後の業務効率の差は、ここで生まれます。
まとめ
契約棚卸しは、多くの法務部門が積年の課題として抱えてきた業務です。人手の限界、派遣外注のコスト、OCRの精度——どれをとっても、これまでは「完遂が困難」と言わざるを得ませんでした。
しかし、自律型AIエージェント × オープン型CLM の組み合わせによって、ようやく現実的な解決策が見えてきました。エージェントが大量の契約原本を読み、メタデータを抽出し、CLMに直接書き込む。法務担当者はサンプリングレビューと業務設計に専念する。そして、初期棚卸しで構築した仕組みが、そのまま運用フェーズの継続棚卸しにも活きる。
「AIは選び、契約は1箇所に集める」——この思想は、契約棚卸しという業務にこそ、最も強く当てはまります。AIの進化スピードを取り込みつつ、契約データという企業の重要資産を一元管理し続ける。その両立を可能にするのが、オープン型CLMの設計思想です。
これからCLM導入を検討する、あるいはすでに導入したCLMをより高度に活用したいと考えている法務責任者の方は、まずは小規模な範囲(特定の契約類型、特定の事業部)で、AIエージェント × オープン型CLMによる棚卸しを試してみることをおすすめします。一度動き出せば、その効率と継続性の違いに、すぐに気づいていただけるはずです。
本記事はContractS株式会社のコンテンツマーケティングチームが、エンタープライズ企業の法務・調達・CTO室向けに執筆したものです。AIエージェントを契約業務に組み込む際の判断は、必ず自社の業務特性・リスク許容度に応じて行ってください。本記事はリーガルアドバイスではありません。